课程价格 :
¥1599.00
剩余名额
0
-

学习时长
9周/建议每周至少6小时
-

答疑服务
专属微信答疑群/讲师助教均参与
-

作业批改
每章节设计作业/助教及时批改评优
-

课程有效期
一年/告别拖延,温故知新





- 1:【文档】百度文心开课仪式
- 第1章: TensorRT介绍
- 第1节: TensorRT是什么
- 2:【课件】TensorRT介绍
- 3:【视频】TensorRT是什么
- 第2节: TensorRT整体工作流程与优化策略
- 4:【视频】TensorRT整体工作流程与优化策略
- 第3节: TensorRT的组成与基本使用流程
- 5:【视频】TensorRT使用的基本流程
- 第4节: TensorRT DEMO:SampleMNIST
- 6:【视频】demo
- 第5节: TensorRT进阶
- 7:【视频】TensorRT进阶
- 第6节: DEMO演示
- 8:【视频】Demo演示
- 第2章: TensorRT转换ONNX模型
- 第1节: ONNX 介绍
- 9:【课件】 TensorRT 转换 ONNX模型 v2.0
- 10:【视频】ONNX介绍
- 第2节: 背景知识
- 11:【视频】背景知识 lower概念
- 第3节: TRT转换模型的主要痛点
- 12:【视频】TRT转换模型的主要痛点
- 第4节: onnx-parser & onnx-graphsurgen
- 13:【视频】onnx-parser & onnx-graphsurgen
- 第5节: 实践
- 14:【视频】实践上:Transformer模型优化 解决不支持的算子
- 15:【视频】 实践下:Transformer模型优化 合并LayerNorm算子
- 第6节: polygraphy
- 16:【视频】 polygraphy
- 第3章: 模型框架与模型转换方式介绍
- 17:【课件】Ernie项目-模型框架与模型转换方式介绍
- 18:资料分享
- 第1节: 课程介绍和模型介绍
- 19:【视频】课程介绍和模型介绍
- 第2节: 转换方式对比
- 免费 20:【视频】转换方式对比
- 第4章: 环境搭建
- 第1节: 加速节点介绍
- 21-1:【课件】Ernie项目-开始节点
- 21-2:【视频】 加速节点介绍
- 21-3:代码
- 第2节: 环境和目录结构介绍
- 22:【视频】环境和目录结构介绍
- 第3节: 测试数据介绍
- 23:【视频】 测试数据介绍
- 第4节: C++ infer与评价标准
- 24:【视频】 C++ infer与评价标准
- 第5节: 构建方式介绍
- 25:【视频】 构建方式介绍
- 第6节: 开始节点实战
- 26-1:【视频】开始节点实战
- 26-2:L4 Project:环境搭建
- 第7节: 作业
- 27:【作业说明】
- 28:【作业】第四章
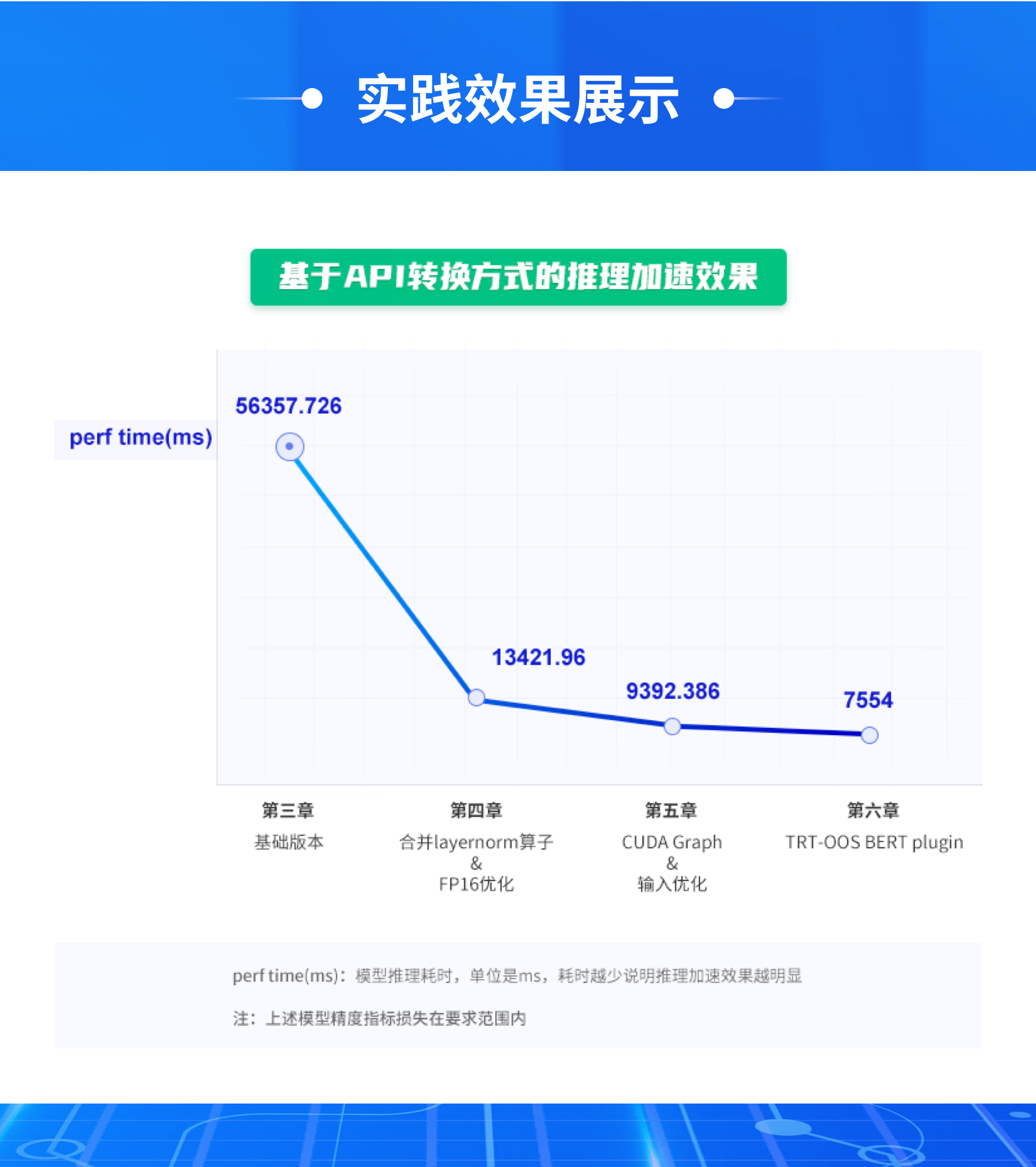
- 第5章: 第一阶段优化方法:性价比最高的推理加速优化
- 29:【课件】Ernie项目-第一阶段优化方法
- 第1节: 加速节点概况
- 30:【视频】加速节点概况
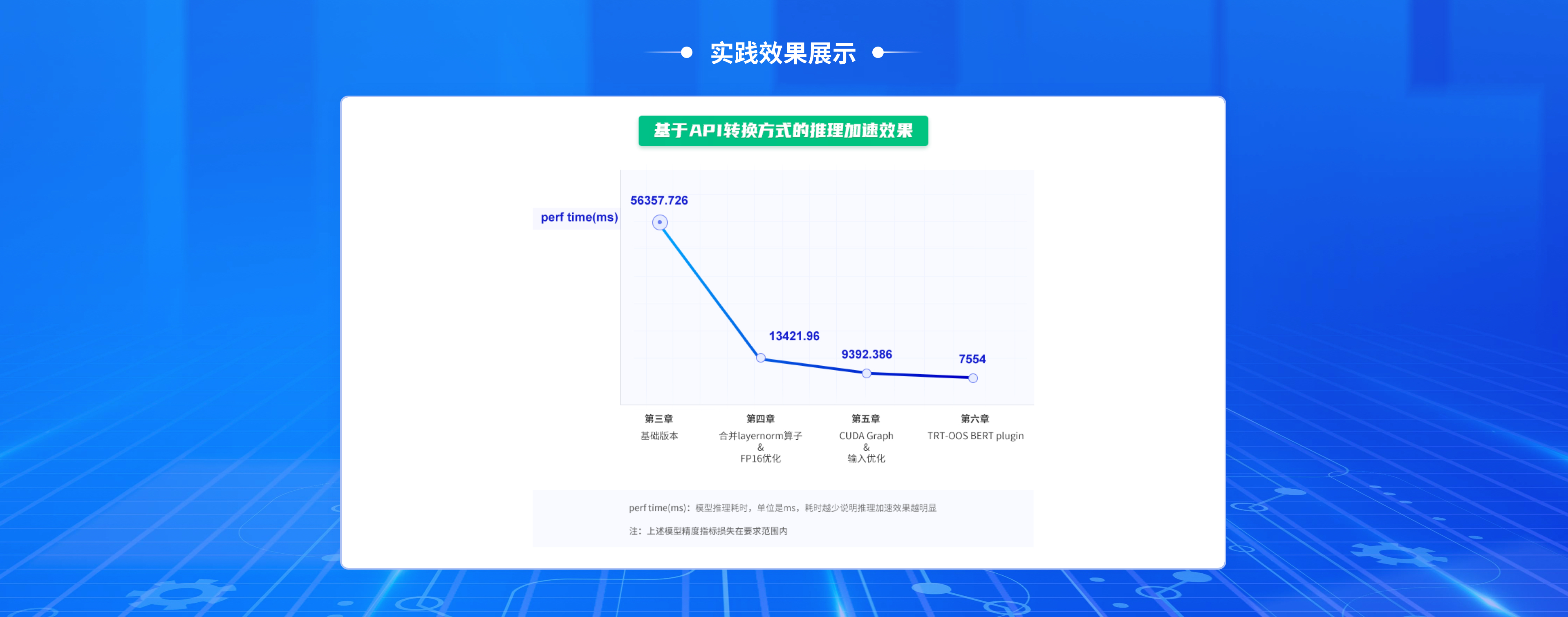
- 第2节: FP16优化
- 31: 【视频】FP16优化
- 第3节: 合并LayerNorm算子
- 32:【视频】合并layernorm算子
- 第4节: 作业
- 33-1:作业描述
- 33-2:【作业】第五章
- 第6章: 第二阶段优化方法:CUDA Graph & 输入优化
- 34:【课件】L6 输入优化&CUDA Graph
- 第1节: 输入优化方法:减少数据传输次数&提高传输速度
- 35:【视频】减少传输次数&提高传输速度
- 第2节: 输入优化方法:batching与overlap
- 36: 【视频】batching与overlap
- 第3节: 补充知识:CUDA stream
- 37-1:【课件】CUDA C编程:CUDA stream
- 37-2:【视频】CUDA Stream介绍
- 37-3:【视频】CUDA Stream为什么有效
- 37-4:【视频】CUDA Stream默认流的表现
- 第4节: 什么是CUDA Graph以及为什么要做
- 38-1:【课件】CUDA Graph
- 38-2:【视频】什么是CUDA Graph以及为什么要做
- 第5节: 如何做CUDA Graph
- 39:【视频】如何做CUDA Graph
- 第6节: CUDA Graph缺点及解决方案
- 40:【视频】CUDA Graph缺点及解决方案
- 第7节: 实战:输入优化与 CUDA Graph
- 41:L6 Project:输入优化与 CUDA Graph
- 第8节: 作业
- 42-1:【文档】作业说明
- 42-2:【作业】第六章
- 第7章: 第三阶段优化方法:大规模算子合并加速
- 43:【课件】Ernie项目 算子合并
- 第1节: 为什么要做大规模算子合并
- 44:【视频】为什么要做大规模算子合并
- 第2节: 模型结构详解
- 45:【视频】模型结构讲解
- 第3节: 加速策略1:合并Encoder模块以及Input Embedding模块
- 46:【视频】合并Encoder模块以及Input Embedding模块
- 第4节: 加速策略2:加速Attention模块
- 47:【视频】 加速Attention模块
- 第5节: 加速策略3:去除冗余计算等策略
- 48:【视频】去除冗余计算等策略
- 第8章: 终点:结合开源方案
- 第1节: 终点:结合开源方案
- 49:【课件】终点:结合开源方案
- 第2节: 基础版本开源代码
- 50:【视频】基础版本开源代码
- 第3节: 进阶fused版本
- 51:【视频】进阶fused版本
- 第9章: 进一步深度加速的方法探讨
- 52:【课件】Ernie项目-进阶节点
- 第1节: INT8 量化
- 53:【视频】INT8量化
- 第2节: VarLen减少零填充带来的GPU计算开销
- 54:【视频】var len变长
- 第3节: 稀疏剪枝等模型优化算法
- 55:【视频】稀疏剪枝等模型优化方法
- 第10章: 课程直播答疑12.1
- 56:【直播】课程答疑